Formalmente, podemos definir un árbol de la siguiente forma:
- Caso base: un árbol con sólo un nodo (es a la vez raíz del árbol y hoja).
- Un nuevo árbol a partir de un nodo nr y k árboles
 de raíces
de raíces  con
con  elementos cada uno, puede construirse estableciendo una relación padre-hijo entre nr y cada una de las raíces de los k árboles. El árbol resultante de
elementos cada uno, puede construirse estableciendo una relación padre-hijo entre nr y cada una de las raíces de los k árboles. El árbol resultante de  nodos tiene como raíz el nodo nr, los nodos son los hijos de nr y el conjunto de nodos hoja está formado por la unión de los k conjuntos hojas iniciales. A cada uno de los árboles Ai se les denota ahora subárboles de la raíz.
nodos tiene como raíz el nodo nr, los nodos son los hijos de nr y el conjunto de nodos hoja está formado por la unión de los k conjuntos hojas iniciales. A cada uno de los árboles Ai se les denota ahora subárboles de la raíz.
- El recorrido en preorden, también llamado orden previo consiste en recorrer en primer lugar la raíz y luego cada uno de los hijos en orden previo.
- El recorrido en inorden, también llamado orden simétrico (aunque este nombre sólo cobra significado en los árboles binarios) consiste en recorrer en primer lugar A1, luego la raíz y luego cada uno de los hijos
 en orden simétrico.
en orden simétrico. - El recorrido en postorden, también llamado orden posterior consiste en recorrer en primer lugar cada uno de los hijos en orden posterior y por último la raíz.
Tipos de arboles
- Árboles Binarios
- Árbol de búsqueda binario auto-balanceable
- Árboles AVL
- Árboles Rojo-Negro
- Árbol AA
- Árbol de búsqueda binario auto-balanceable
- Árboles Multicamino
- Árboles B (Arboles de búsqueda multicamino autobalanceados)
- Árbol-B+
- Árbol-B*
Las operaciones comunes en árboles son:
- Enumerar todos los elementos.
- Buscar un elemento.
- Dado un nodo, listar los hijos (si los hay).
- Borrar un elemento.
- Eliminar un subárbol (algunas veces llamada podar).
- Añadir un subárbol (algunas veces llamada injertar).
- Encontrar la raíz de cualquier nodo.
- Representar cada nodo como una variable en el heap, con punteros a sus hijos y a su padre.
- Representar el árbol con un array donde cada elemento es un nodo y las relaciones padre-hijo vienen dadas por la posición del nodo en el array

Recorridos
Al visitar los nodos de un árbol existen algunas maneras útiles en las que se pueden ordenar sistemáticamente los nodos de un árbol.
Los ordenamientos más importantes son llamados: preorden, post-orden y en-orden y se definen recursivamente como sigue:
Si un árbol T es nulo, entonces, la lista vacía es el listado preorden, post-orden y en-orden del árbol T.
Si T consiste de un sólo nodo n, entonces, n es el listado preorden, post-orden y en-orden del árbol T.
Los algoritmos de recorrido de un árbol binario presentan tres tipos de actividades comunes:
• visitar el nodo raíz
• recorrer el subárbol izquierdo
• recorrer el subárbol derecho
Estas tres acciones llevadas a cabo en distinto orden proporcionan los distintos recorridos del árbol.
Recorrido en PRE-ORDEN:
• Visitar el raíz
• Recorrer el subárbol izquierdo en pre-orden
• Recorrer el subárbol derecho en pre-orden
Recorrido EN-ORDEN
• Recorrer el subárbol izquierdo en en-orden • Visitar el raíz • Recorrer el subárbol derecho en en-orden
Recorrido en POST-ORDEN
• Recorrer el subárbol izquierdo en post-orden
• Recorrer el subárbol derecho en post-orden
• Visitar el raíz

Clases de arbol
Con la clase JTree, se puede mostrar un árbol de datos. JTree realmente no contiene datos, simplemente es un vista de ellos. Aquí tienes una imagen de un árbol. 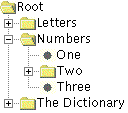
Los nodos que no sean hojas pueden tener cualquier número de hijos, o incluso no tenerlos. En la figura anterior, el aspecto-y-comportamiento marca los nodos que no son hojas con un carpeta. Normalmente el usuario puede expandir y contraer los nodos que no son hojas -- haciendo que sus hijos sena visibles o invisibles -- pulsando sobre él. Por defecto, los nodos que no son honas empiezan contraidos.
Cuando se inicializa un árbo, se crea un ejemplar de TreeNode para cada nodo del árbol, incluyendo el raíz. Cada nodo que no tenga hijos es una hoja. Para hacer que un nodo sin hijos no sea una hoja, se llama al método setAllowsChildren(true) sobre él.





No hay comentarios:
Publicar un comentario